Abstract
In this work, we propose an innovative model that combines the emerging capabilities of foundation models for segmentation with a high-performing few-shot classifier, adapting the latter to be effectively applied in the context of semantic segmentation. This segmentation framework is expressly designed to be embedded in a target-aware grasp synthesis model, as demonstrated by the proposed method. Our experiments highlight how the proposed model overcomes limitations in performance, offering advancements both in few-shot semantic segmentation and real-world grasp synthesis with semantic-awareness.
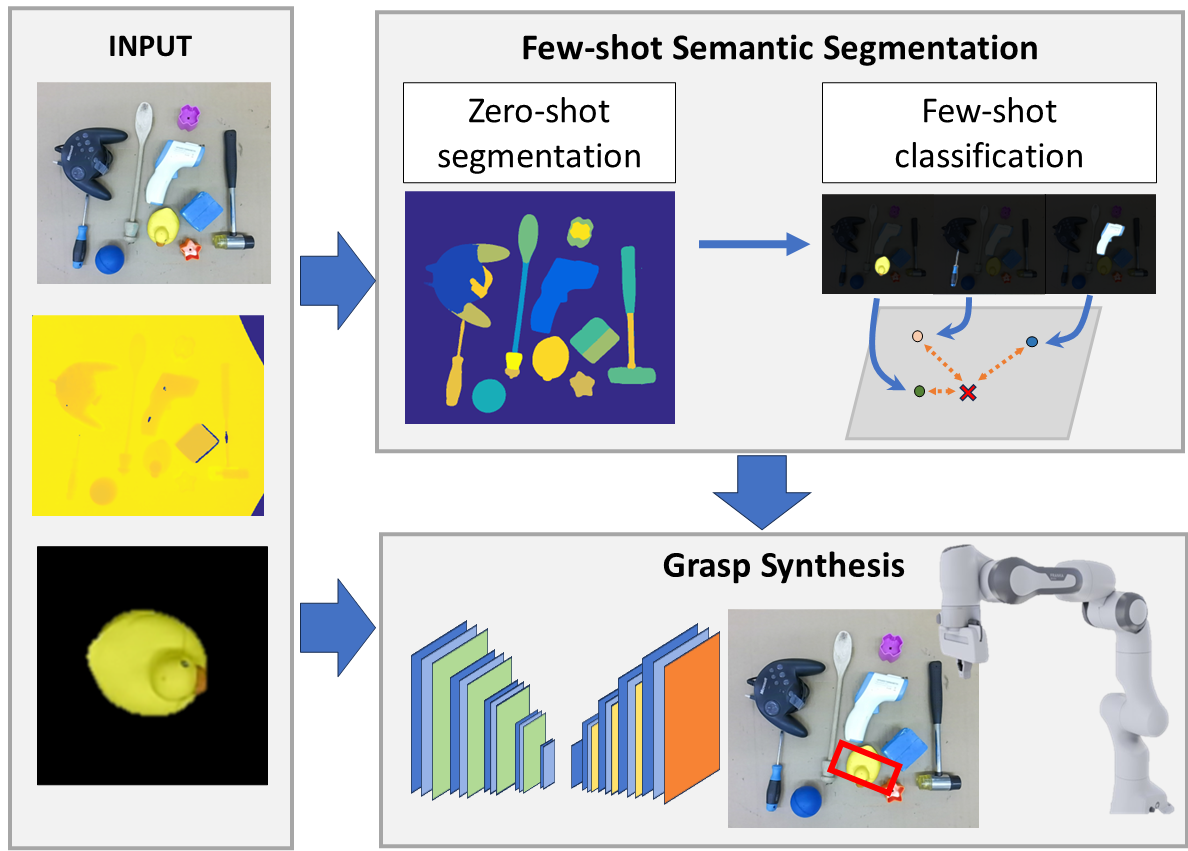
Few-shot semantic segmentation
The core part is the few-shot segmentation module that leverages the capabilities of foundation models with the high accuracy of few-shot classification models.
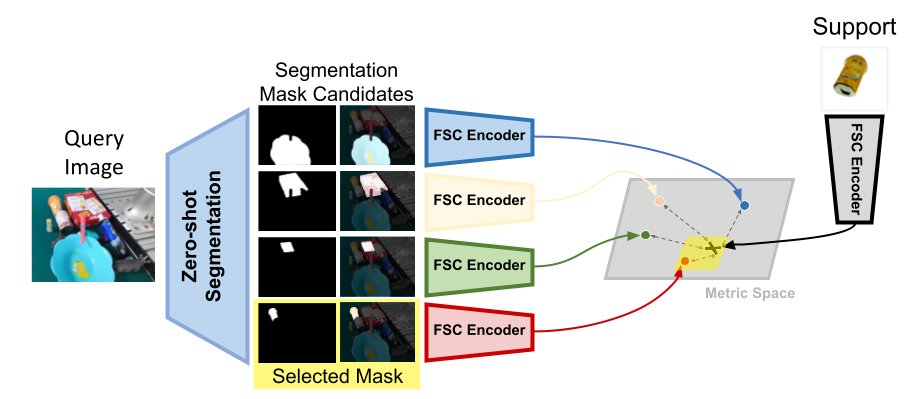
Few-shot semantic segmentation
The module can be included in grasp synthesis, in which it offers knowledge about the semantic given only few examples of the target.
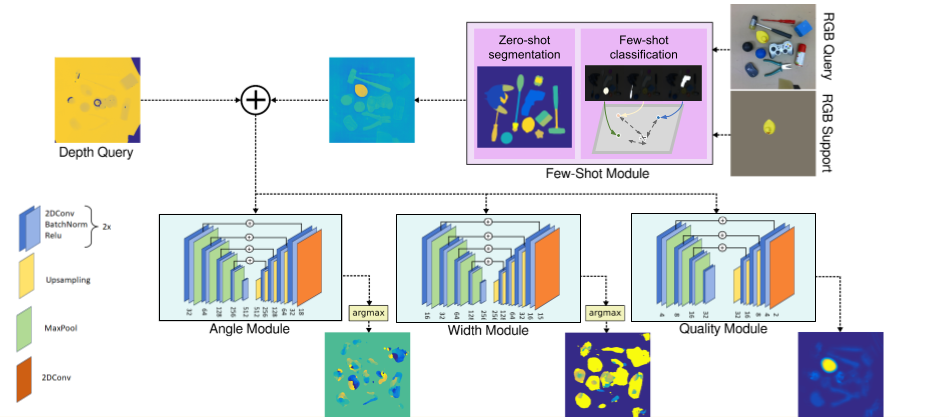
Few-shot semantic grasping
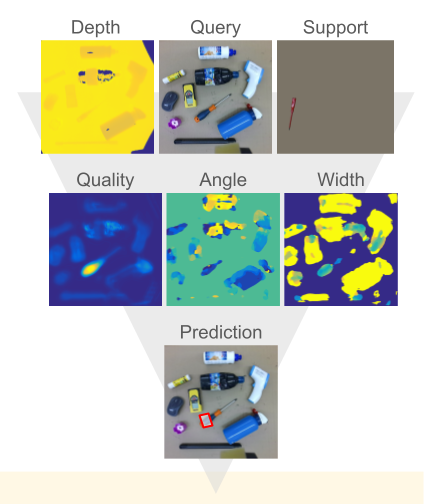
Thank to the impressive results of the few-shot segmentation module, the grasp-shyntesis can generalize to new objects, not represented in the training set, with only few-examples

Few-shot instance recognition
Thanks to example, it can also choose the most similar instance among different possible targets of te same class

Generalization to different instances
It generalize to novel classes, even when the visual characteristics are different compared to the examples
BibTeX
@misc{barcellona2024grasp,
title={Show and Grasp: Few-shot Semantic Segmentation for Robot Grasping through Zero-shot Foundation Models},
author={Leonardo Barcellona and Alberto Bacchin and Matteo Terreran and Emanuele Menegatti and Stefano Ghidoni},
year={2024},
eprint={2404.12717},
archivePrefix={arXiv},
primaryClass={cs.RO}
}